ElasticSearch 集群的工作原理
说说 Elasticsearch 存储原理,相信有不少人都会关心数据存储在ES中的存储容量。
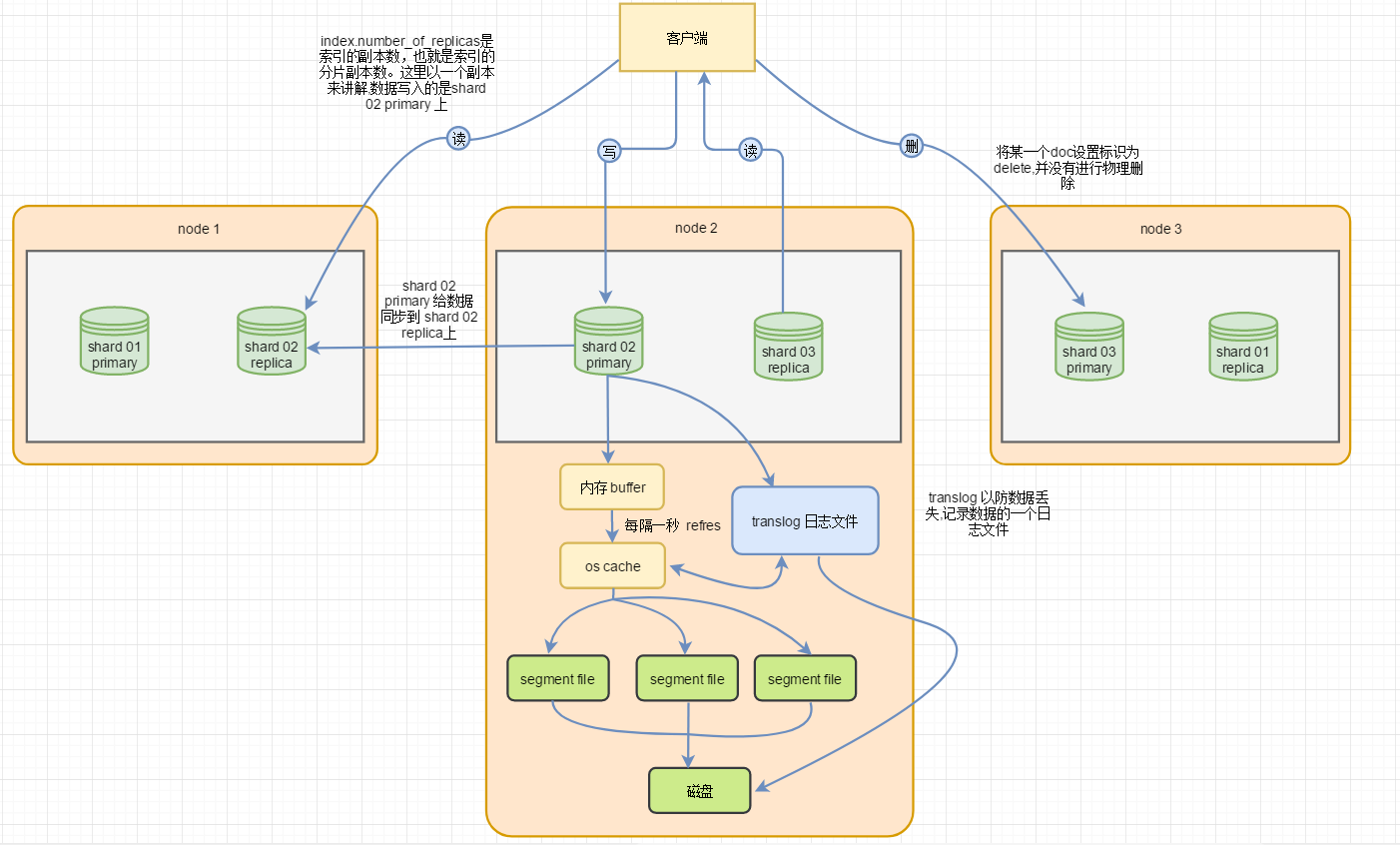
1. 读写架构
2. 写入过程
- 客户端选择一个node发送请求过去,当前node会去找对应的主分片(primary shard) 的 node 如果主分片不在当前节点上,就将请求转发给主分片的 node。
- 主分片node在接收到请求document,进行数据写入。然后将数据同步到replica node。(注意如果你没有指定 doc id,document会自动给你分配一个全局唯一的doc id)
- 当主分片(primary shard) 跟 replica node 写完时就响应客户端,代表本次写入成功
3. 查询过程
- 客户端发送请求到node节点上,当前 node将判断 document 存储哪些 node 上并且进行请求转发给当前 node 。(这里会使用round-robin随机轮询算法,进行负载均衡)
- node接收到document 后给doc id 进行 hash去对应的 shard 上进行查询,然后给 document 返回给客户端
4. 原理
- 数据写入内存 buffer,同时写入一份到translog日志文件。在buffer中的数据是无法搜索的
- 默认是每隔一秒,将 buffer 中数据生成一个新的segment file 写进去,写入前会先进入os cache。如果buffer中有数据就进行refresh操作。数据这时就可以查询了
- buffer中的数据每次刷新到os cache就会被清空。translog就不会而且会变得越来越大。当translog达到一定长度的时候,就会触发commit操作
- commit操作就是将buffer中现有数据refresh到os cache中去,清空buffer。然后将os cache中目前所有的数据都fsync到磁盘文件中。在清空translog日志文件
- 删除操作:将document 标识为 dalete,并没有进行物理删除
- 修改操作:将document 标识为 dalete,并没有进行物理删除,然后在添加一条数据
- 默认是1秒钟buffer每次refresh一次,就会产生一个segment file,segment file会越来越多
- 当segment file到一定程度时会进行合并将多个segment file 合并为一个 segment file
- 同时将标识为deleted的doc给物理删除掉,然后将新的segment file写入磁盘。在更新segment file的标识
5. 数据丢失
translog 每秒5会进行持久化刷新到磁盘。translog 之前是在 os cache的(缓冲区里面)。如果这时宕机了最多丢失5秒数据。 也有不丢失数据的方法,每次强制将translog刷新到磁盘,然后在算成功写入。这样就会大大降低吞吐量。